Determining hydrogen positions in crystalline solids has long been a bottleneck in materials characterization. Hydrogen’s low X-ray scattering power makes standard diffraction unreliable, while neutron diffraction, requires large facilities and sample quantities that are orders of magnitude more expensive.
Consequently, crystallographic databases routinely store structures where hydrogen positions are absent or estimated from heuristics, introducing systematic errors into geometry dependent property predictions.
Researchers at the Paul Scherrer Institute (PSI), in collaboration with teams from the University of Parma and the University of Modena, developed a score-based diffusion model adapted from computer vision inpainting techniques to reconstruct missing hydrogen positions in host crystal structures.
The study, published in npj Computational Materials in June 2026, reports a Lower Energy or Structural (LES) matching rate exceeding 97% across a test set of hydrogen-containing materials drawn from the MC3D database – rising above 99% when structures flagged as theoretical in the source database are excluded (Reents et al., 2026).
Related: Scientists Turn Plastic Waste and Dead Battery Acid Into H2 Fuel Using Sunlight
Why Hydrogen Positions Are Notoriously Difficult to Determine Experimentally
Hydrogen scatters X-rays weakly, but its high incoherent neutron scattering cross section generates noise that degrades structural refinements (Reents et al., 2026). Neutron diffraction is the H-positioning reference, but facility and sample constraints limit it to targeted studies over routine curation.
Crystallographic databases like the Cambridge Structural Database, ICSD, and COD often place hydrogen atoms based on assumed geometry rather than direct measurement. These approximated positions propagate through DFT calculations and MLIP training pipelines, leading to unreliable property predictions. It is a direct problem for researchers working on hydrogen storage, photocatalysis, or fuel cell materials.
Also Read: Residence Time Distribution in CSTR and PFR – Model with Python Code
How the Score-Based Diffusion Inpainting Model Works
The PSI team built on Microsoft’s MatterGen model, a diffusion model originally trained to generate novel, stable crystal structures with desired properties.
Score-based diffusion models learn to reverse a noise-addition process: during training, Gaussian noise is progressively added to known structures according to a stochastic differential equation, and the model learns to predict and remove that noise to recover the original atomic configuration.
The core equation governing the forward noising process:
dx = f(x, t) dt + g(t) dW
Symbol definitions:
- x is the atomic positions (fractional coordinates within the unit cell)
- t is the continuous time variable indexing the noise level (t = 0 is the clean structure, t = T is pure noise)
- f(x, t) is the drift coefficient (controls the deterministic evolution of the process)
- g(t) is the diffusion coefficient (scales the magnitude of noise injection)
- dW is the standard Wiener process increment (Gaussian noise)
Physical meaning: The model learns the score function ∇ₓ log p(x), the gradient of the log-probability density of clean atomic configurations, allowing it to iteratively denoise a randomly initialized set of hydrogen positions toward a configuration consistent with the known host structure.
The core contribution is adapting TD-Paint , an image inpainting algorithm – to crystal structures. Rather than applying uniform noise, TD-Paint uses variable noise at the pixel level, conditioning denoising on known regions while reconstructing missing ones.
In this context, known non-hydrogen atomic positions remain fixed throughout the denoising trajectory, while hydrogen site coordinates are iteratively predicted (Reents et al., 2026).
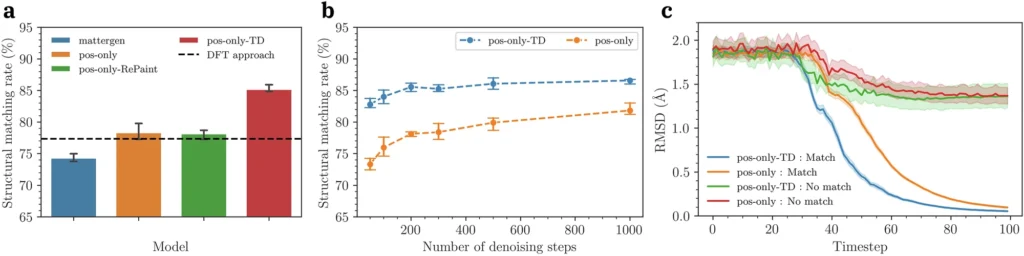
Key Results: Performance Across Structural and Energy Matching
Generated hydrogen candidates are refined through constrained H-position relaxation using the NequIP potential, then full unconstrained relaxation.
Success is measured by structural matching via pymatgen’s StructureMatcher and energetic matching – where the predicted configuration is more stable than the original database entry, confirmed by DFT.
| Model / Approach | Single-Trial Matching Rate | Key Characteristic |
|---|---|---|
| MatterGen baseline | Lowest among tested models | No task-specific retraining |
| pos-only (retrained) | Improved over baseline | Denoises positions only, uniform noise |
| pos-only-RePaint | Comparable to pos-only | Reduces variance; 1000+ steps required |
| pos-only-TD (final model) | Highest single-trial rate | Variable noise per site; 300 steps sufficient |
| DFT-based reconstruction | ~77% (subset) | Physics-based; computationally expensive |
| LES rate (30 trials, DFT dataset) | >97% | Structural + energetic match combined |
| LES rate (EXP dataset, no theoretical structures) | >99% | Starting from raw experimental host structures |
When no structural match is found, the model’s prediction is typically still energetically favorable – 84.2% of non-matching DFT cases and 77.4% of experimental cases relaxed to lower energy than the database reference (Reents et al., 2026).
This says the model finding genuinely more stable geometries than historically approximated entries. Median energy changes during MLIP relaxation were just 2 meV/atom (DFT structures) and 5 meV/atom (experimental structures), confirming that generated candidates are already near their local energy minima.
What This Advances Over DFT-Only Approaches
Prior DFT based approaches achieved around 77% structural matching on the overlapping test subset, rising to 87% when expensive “pinball method” structures are excluded. The pos-only-TD model reached 88% on the same subset with a single trial and improves further with multiple samples (Reents et al., 2026).
The computational advantage is significant. DFT requires iterative self-consistent field calculations whose cost grows with unit cell size and missing hydrogen count. The diffusion model generates predictions in 300 denoising steps, with inference time independent of the number of missing sites. At just 50 steps, pos-only-TD still outperforms the pos-only model at 1000 steps, confirming that TD-Paint’s conditioning efficiently targets the correct structural manifold.
The model is also architecture agnostic: trained in a hydrogen agnostic manner, the same weights transfer directly to other completion tasks such as intercalation site prediction, without retraining.
Related: Personal Carbon Footprint Calculator – Track your CO2 Emissions
Also Read: The Crucial Role of Chemical Engineering in Everyday Life
Limitations and Open Questions
The method requires the number of missing hydrogen sites as an input, typically available from stoichiometry or partial experimental data. Preliminary results for estimating this count appear in the supplementary material.
Generalization beyond the MC3D benchmark dataset to hybrid DFT or complex hydrogen bonding networks remains uncharacterized, and MLIP stability predictions depend on the quality of NequIP’s training set. MatterGen’s stability bias toward lower-energy phases may also affect performance on metastable or defect-containing structures.
Nevertheless, the PSI team demonstrates that diffusion based crystal structure inpainting, trained once on a general dataset and adapted using a computer vision technique, exceeds physics based methods at a fraction of the computational cost.
A 97% LES success rate on experimental host structures positions this as a tool ready for systematic deployment across crystallographic databases and materials property pipelines.
Original Research: Score-based diffusion models for accurate crystal-structure inpainting and reconstruction of hydrogen positions — Reents, T., Cantarella, A., Bercx, M., Bonfà, P., & Pizzi, G. npj Computational Materials, 12, 203 (2026).
References
- Reents, T., Cantarella, A., Bercx, M., Bonfà, P., & Pizzi, G. (2026). Score-based diffusion models for accurate crystal-structure inpainting and reconstruction of hydrogen positions. npj Computational Materials, 12(1), 203. https://doi.org/10.1038/s41524-026-02090-1
- Zeni, C. et al. (2025). A generative model for inorganic materials design. Nature, 639, 624–632. https://doi.org/10.1038/s41586-025-08628-5
- Song, Y. et al. (2021). Score-Based Generative Modeling through Stochastic Differential Equations. arXiv:2011.13456.